In a recent migration project I needed to move nearly 2TB of mailbox data between Exchange 2003 servers in the same organization, to the tune of 100-200GB per day. The first couple days went fine, with excellent performance, but as more mailboxes were moved to the target server and mail delivery processes and user connections increased, move-performance began to degrade to the point that mailbox moves started to spit out generic MAPI errors and failed.
After a quick check of the application log I found a never-ending string of PerfOS 2012 errors:
Event Type: Warning
Event Source: PerfOS
Event ID: 2012
Description:Unable to get system process information from system. The status code returned is in the first DWORD in the data section.
I found very little information online regarding this error, but what I did see was typically related to memory-leaking processes. It’s quote possible that the massive mailbox moves were eating up resources and not allowing the system to reclaim them, as a reboot of the server temporarily resolved the issue. But after moving a large amount of data the same error would return, forcing an almost daily cycle of the server to ‘refresh’ it’s resources.
Since the target server was built with 16GB of RAM and Server 2003 Enterprise Edition, the /3GB and /USERVA boot.ini switches were used. There are a handful of articles covering the usage and importance of this configuration:
- http://support.microsoft.com/kb/823440
- http://support.microsoft.com/kb/328882
- http://technet.microsoft.com/en-us/library/bb124810.aspx
The first article specifically talks about monitoring Free System Page Table Entries which is found in the Memory performance object in Performance Monitor. Throughout the next set of scheduled moves I tracked the value of this counter and observed the same behavioral pattern: starting MSExchangeIS would typically reduce the counter value by 1 third, and then mailbox moves would continually lower the value over time, until it would drop around 600-1000. Around this time the PerfOS messages would reappear in the application log and it was only a matter of time before mailbox moves started to fail.
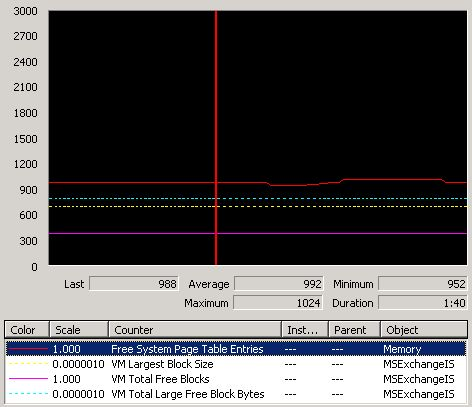
By manually restarting the Exchange Information Store once per day I was able to raise the Free System Page Table Entries to a higher level, but new instances of the PerfOS errors were still appearing in the Application Log. Simply rebooting the server resolved the issue temporarily, but the mass movement of mailbox data was just expediting the same low resources issue that would eventually re-appear under normal operations.
While reviewing MS KB article 316739 I discovered that the recommended /USERVA value of 3030 is only really suggested as a starting point, and the server was only showing about 2000 free system page table entries after the MSExchangeIS service was started, which would decline to nearly 900 before this error would appear in the System log, requiring a reboot.
Event Type: Error
Event Source: Application Popup
Event ID: 333
Description:An I/O operation initiated by the Registry failed unrecoverably. The Registry could not read in, or write out, or flush, one of the files that contain the system’s image of the registry.
By decreasing the USERVA setting by the recommended 64MB increments I was able to increase the observed PTE value above the 24,000 range. So, after a little experimenting I found that a setting of 2900 addressed nearly 35,000 free system PTEs and the server has been stable ever since.